“Optimism is the faith that leads to achievement”
– Helen Keller
Next week, I will be Keynoting the SDL Connect conference in Santa Clara. I will be speaking about Language as the third pillar of data required to create and deliver personalized customer experiences. We are expecting a large audience with representation from many Fortune 500 companies. SDL will be making several significant product announcements at the event and I’ll be setting up Adolfo, SDL’s CEO to make some bold claims about the technical advancements made within their platform. The most significant of which will be the inclusion of Artificial Intelligence within their Machine Translation products.
My speech will focus primarily on the advancements made around understanding content as data and specifically how through the war on terror, the intelligence community developed tools for understanding content and communication that will soon be introduced into the commercial market place. As I was conducting research for the speech, I came across an analysis of speech patterns conducted by research organizations that I want to share with you.
The government had been recording and collecting all of the communication by Fidel Castro leading up to and after the Cuban missile crisis in October of 1962. As I mentioned last week there are many techniques to better understand content; how it belies intent, a deeper understanding of the meaning, and a glimpse into the efficacy of interaction models. This particular report focused on Castro’s speech pattern after the crisis was resolved. The results indicated that after the Cuban Missile Crisis, Castro’s speeches had a simpler syntactic structure, more embodied words, and less negative expressions. It makes sense that after the removal of Soviet protection, Castro was demurred and his style, tone, and tenor changed.
The tool used to conduct this analysis is called the Coh-Metrix. It is an automated linguistic analysis tool that analyzes text on measures of cohesion, syntax, readability, and other characteristics of language and discourse.
Coh-Metrix is sensitive to a wide range of linguistic/discourse features that reflect multiple levels of text complexity and has five orthogonal dimensions:
- Narrativity. Narrative text tells a story, with characters, events, and is closely affiliated with everyday oral conversation.
- Syntactic ease. Sentences with fewer words and simple, less embedded, syntactic structures are easier to process and understand.
- Word concreteness. Concrete words evoke mental images and are more meaningful to the reader than abstract words.
- Referential cohesion. High cohesion text contains explicit words and ideas that overlap across sentences and the entire text
- Deep cohesion. The extent to which the ideas in the text are connected with causal or intentional connectives at the deeper situation model level.
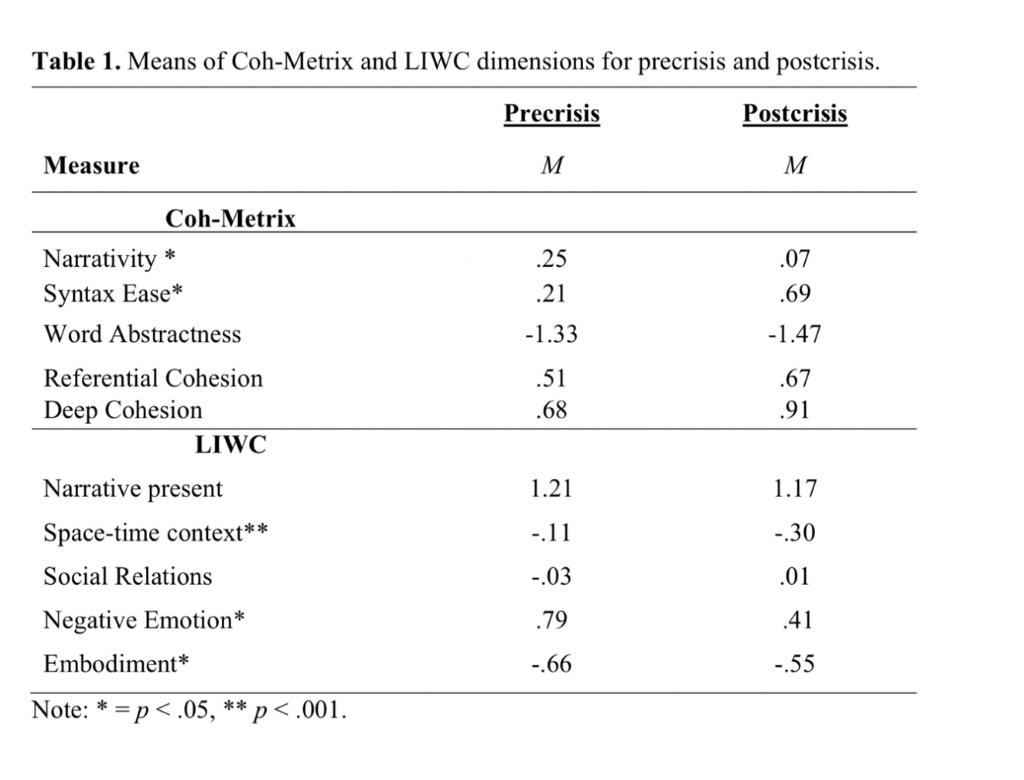
The graph above is a result of the analysis of Castro’s speeches and an example of how we can use machine learning to ingest large amounts of content, then provide our clients information on how they are communicating with their customers. Furthermore; those same techniques can be applied to social media with responses to a brand, to customer satisfaction surveys and rating/review content. We can create a closed-loop understanding of how a brand and its customer are interacting with one another.
Over time, combined with customer profile data, analytics, and behavioral data we will leverage this deeper understanding of the content to tailor experiences that exactly meets the customers’ expectations and needs, but most importantly deliver the experience in language, tone, and familiarity you would expect when talking to a good friend.
Let’s go be great!
Brad